Що таке декодування: повне пояснення процесу відновлення даних
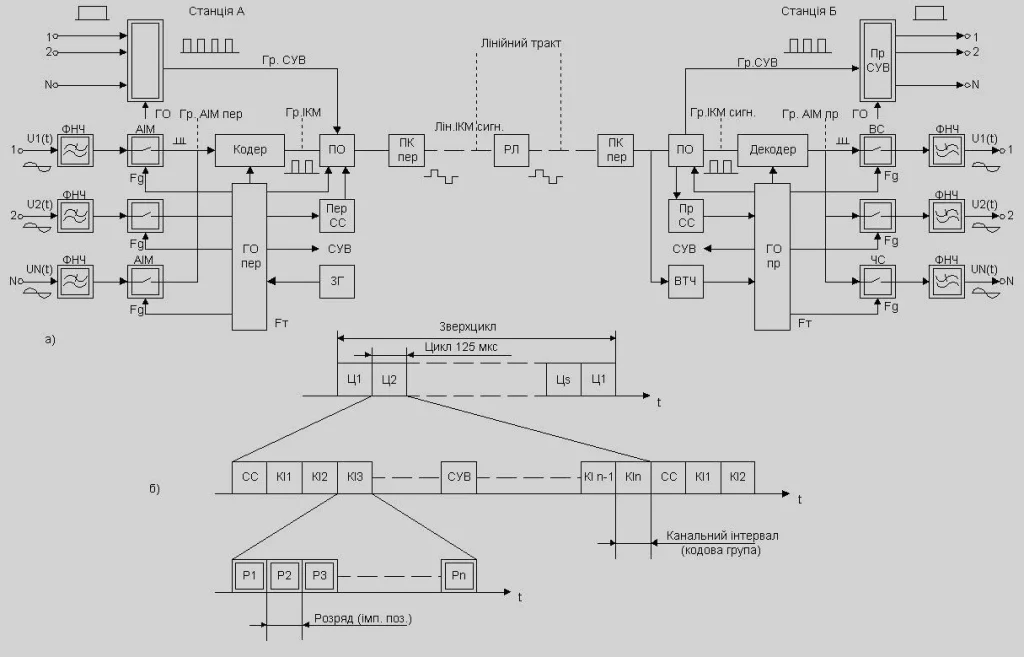
У цифровому світі декодування щодня перетворює хаотичні послідовності бітів і символів на зрозумілі зображення, звуки, тексти та команди. Без цього процесу неможливо було б переглядати відео в потокових сервісах, отримувати повідомлення в месенджерах чи користуватися мобільним інтернетом. Декодування — це систематичне відновлення початкової інформації з її закодованої форми за допомогою заздалегідь відомих правил або алгоритмів.
Процес є прямою протилежністю кодуванню. Якщо під час кодування дані стискають, адаптують до каналу передавання або додають надлишковість для захисту від помилок, то декодування виконує зворотні операції: розпаковує, інтерпретує та відновлює структуру. У теорії інформації, сформульованій Клодом Шенноном у 1948 році, ці два етапи забезпечують надійну передачу повідомлень навіть за наявності шумів і перешкод у каналі зв’язку.
Сьогодні декодування застосовують у найрізноманітніших сферах — від простої обробки текстових файлів до складних алгоритмів у мережах 5G та апаратних декодерах відеокарт. Розуміння його механізмів дозволяє краще оцінити, чому одні технології працюють швидко й надійно, а інші — ні.
Теоретичні основи процесу декодування
У найзагальнішому вигляді код — це набір правил відповідності між символами або сигналами однієї системи та елементами іншої. Декодер знає ці правила і застосовує їх у зворотному напрямку. Коли код є взаємно однозначним (бієкцією), відновлення відбувається однозначно й без втрат. У реальних системах зв’язку канал завжди додає шум, тому декодування часто стає ймовірнісним: алгоритм обирає найбільш правдоподібний варіант серед кількох можливих.
Класичний приклад — азбука Морзе. Кожна літера чи цифра закодована комбінацією крапок і тире. Приймач, отримавши послідовність сигналів, застосовує таблицю відповідностей і відновлює текст. Якщо сигнал спотворений, досвідчений оператор або сучасний алгоритм може «вгадати» пропущений символ за контекстом. У цифрових системах цю роль виконують математичні моделі та надлишкові дані, додані під час кодування.
Важливо розрізняти декодування та дешифрування. Перше відновлює форму даних згідно з відкритими правилами кодування (наприклад, UTF-8 чи H.264). Друге — це відновлення змісту зашифрованого повідомлення, яке потребує секретного ключа. Змішування цих понять часто призводить до непорозумінь у технічній документації.
Декодування текстової інформації та символів
Найпоширеніший тип декодування в повсякденному програмному забезпеченні — обробка текстових даних. Кожен символ у комп’ютері зберігається як число. Таблиця кодів визначає, яке число відповідає якій літері, цифрі чи знаку. Декодер зчитує послідовність байтів і за правилами таблиці перетворює їх на символи.
Стандарт UTF-8 став домінуючим завдяки ефективності та сумісності. Він використовує змінну довжину: латинські літери займають один байт, кирилиця — два, а східноазійські ієрогліфи — до чотирьох. Декодер аналізує перший байт і визначає, скільки наступних байтів належать до того самого символу. Помилка в цій логіці миттєво призводить до появи «кракозябрів» — набору випадкових символів замість нормального тексту.
Base64 — ще один поширений метод. Він перетворює довільні двійкові дані на текстовий рядок, використовуючи лише 64 символи алфавіту. Три байти (24 біти) групуються в чотири шестибітні значення, кожне з яких замінюється відповідним символом. Декодування виконує зворотну операцію, ігноруючи символи переносу рядка та правильно обробляючи символи доповнення «=». Цей метод широко застосовують в електронній пошті, веб-API та вкладених файлах JSON.
Декодування мультимедійного контенту
Відеодекодування — один із найскладніших і водночас найоптимізованіших процесів у сучасній техніці. Стандарт H.264 (AVC), прийнятий у 2003 році, досі залишається найпоширенішим завдяки балансу між якістю та обсягом даних. Декодер отримує стиснений бітовий потік і виконує послідовність операцій у зворотному порядку до кодування.
Спочатку відбувається ентропійне декодування — відновлення коефіцієнтів квантування та векторів руху. Далі застосовується зворотне квантування та зворотне дискретне косинусне перетворення, яке повертає різницеві дані кадру. Для міжкадрового прогнозування (P- та B-кадри) декодер використовує вектори руху, щоб скопіювати відповідні блоки з попередніх або наступних опорних кадрів і додати до них відновлені різниці. Завершальний етап — фільтр деблокінгу, який згладжує артефакти на межах блоків.
Сучасні пристрої майже завжди використовують апаратні декодери, вбудовані в процесори та відеокарти. Вони дозволяють відтворювати відео 4K і 8K з мінімальним навантаженням на центральний процесор і низьким енергоспоживанням. Програмні декодери (наприклад, на базі FFmpeg) застосовують, коли потрібна гнучкість або підтримка нових форматів, таких як AV1.
Завадостійке декодування в сучасних мережах зв’язку
У реальних каналах зв’язку завжди присутні перешкоди. Завадостійке кодування додає до корисних даних надлишкові біти, які дозволяють декодеру виявляти й виправляти помилки. Декодування в таких системах — це не просто зворотне перетворення, а складний ітеративний або ймовірнісний процес.
Коди Хеммінга — класичний приклад. Вони додають кілька бітів парності таким чином, що положення помилки в блоці можна визначити за синдромом. Сучасні системи використовують значно складніші конструкції. У стандарті 5G NR для каналів передавання даних застосовують LDPC-коди (коди з низькою щільністю перевірок на парність). Їхня розріджена матриця перевірок дозволяє ефективно виконувати ітеративне декодування методом поширення переконань (belief propagation). Це забезпечує високу пропускну здатність і можливість паралельної обробки великих блоків даних.
Для керуючих каналів 5G обрано полярні коди. Вони грунтуються на явищі поляризації каналів: частина синтетичних підканалів стає майже безшумною, а частина — дуже шумною. Декодер послідовного скасування (successive cancellation) або його вдосконалена версія зі списком (SCL) поступово приймає рішення щодо кожного біта інформації, використовуючи попередні результати для уточнення наступних. Такий підхід дає близьку до граничної ефективність при коротких довжинах блоків, характерних для керуючої інформації.
Саме завдяки сучасним алгоритмам завадостійкого декодування мобільні мережі забезпечують стабільний зв’язок навіть за високої швидкості руху абонента чи в умовах щільної міської забудови.
Практичні приклади та поширені проблеми декодування
У програмуванні декодування зустрічається буквально на кожному кроці. Функція JSON.parse у JavaScript або json.loads у Python перетворює текстовий рядок на об’єкти та масиви — це класичне декодування структурованих даних. Бібліотеки URL-декодування замінюють послідовності «%XX» на відповідні байти. Сканери QR-кодів спочатку перетворюють зображення на двійкову матрицю, потім застосовують корекцію помилок за кодом Ріда-Соломона і нарешті витягують корисні дані.
Найпоширеніша проблема — невідповідність таблиць кодування. Файл, збережений у кодуванні Windows-1251, відкритий як UTF-8, видає набір нерозбірливих символів. Виправлення полягає у правильному вказанні кодової сторінки на етапі відкриття файлу або в налаштуваннях бази даних. Інша часта ситуація — відсутність або пошкодження заголовків у відеофайлах. У таких випадках декодер не може визначити параметри потоку (роздільну здатність, профіль кодека), і відтворення стає неможливим або супроводжується артефактами.
| Тип декодування | Приклад коду чи формату | Основний механізм | Сфера застосування |
|---|---|---|---|
| Символьне | UTF-8, Base64 | Змінна довжина байтів або групування бітів | Текстові файли, веб, електронна пошта |
| Мультимедійне | H.264 / AV1 | Зворотне перетворення + компенсація руху | Відеостримінг, відеоконференції |
| Завадостійке | LDPC, полярні коди | Ітеративне або послідовне декодування з корекцією помилок | Мобільний зв’язок 5G, супутникові системи |
| Структуроване | JSON, QR-код | Синтаксичний розбір + корекція помилок | API, мобільні застосунки, логістика |
Інформація у таблиці узагальнена за матеріалами Вікіпедії та ВУЕ.
Неправильне налаштування кодування символів або відсутність необхідних кодеків на пристрої користувача залишається однією з найчастіших причин технічних проблем при обміні даними між різними платформами.
У практиці розробки та експлуатації систем важливо передбачати можливі сценарії помилок декодування ще на етапі проєктування. Багато сучасних бібліотек автоматично визначають кодування за сигнатурами або застосовують евристики для відновлення пошкоджених даних. У критичних системах (медичне обладнання, авіація, фінансовий сектор) застосовують багаторівневе декодування з перевірками цілісності на кожному етапі.
Декодування — це фундаментальна операція, що лежить в основі всієї цифрової інфраструктури. Від простої таблиці кодів до складних ітеративних алгоритмів у мережах 5G воно забезпечує можливість зберігати, передавати та відтворювати інформацію з максимальною точністю та ефективністю. У міру зростання обсягів даних і вимог до швидкості зв’язку роль якісного декодування лише зростатиме, а алгоритми ставатимуть ще більш оптимізованими та енергоефективними.